SemiCOL Challenge Data
Training Data: Structure
The training data consists of two different dataset types: manually annotated whole-slide image regions and whole-slide images (WSI) that are weakly labeled (tumor tissue present in the slide: yes/no). All whole-slide images used for the generation of the datasets were anonymized. All WSIs in the weakly labeled datasets were cut into regions (see more information below)

Figure 1. Structure of SemiCOL challenge training data.
Table 1. Characteristics of the training data/datasets
|
Dataset |
Source |
WSI, n (TU/BEN) |
Scanner |
MPP |
Image format |
Compression |
|
DS_M_1 |
University Hospital Cologne, Lab 1 |
10 |
Hamamatsu S360 |
0.5000 |
PNG |
Original / scanner |
|
DS_M_2 |
University Hospital LMU, Munich |
10 |
Leica GT450 |
0.5000 |
PNG |
Original / scanner |
|
DS_W_1 |
University Hospital Cologne, Lab 1 |
100* (50/50) |
Hamamatsu S360 |
0.4609 |
OME TIFF |
JPEG2000 lossy |
|
DS_W_2A# |
Hospital Wiener Neustadt |
100* (50/50) |
Hamamatsu S360 |
0.4609 |
OME TIFF |
JPEG2000 lossy |
|
DS_W_2B# |
Hospital Wiener Neustadt |
100* (50/50) |
Leica GT450 |
0.5266 |
OME TIFF |
JPEG2000 lossy |
|
DS_W_3 |
University Hospital LMU, Munich |
100* (50/50) |
Leica GT450 |
0.5246 |
OME TIFF |
JPEG2000 lossy |
|
DS_W_4 |
University Hospital Bern |
99* (50/49) |
3DHISTECH P1000 |
0.4862 |
OME TIFF |
JPEG2000 lossy |
Abbreviations: WSI – whole-slide image, MPP – Mikron per pixel, TU – WSIs with tumor, BEN – WSIs with only benign tissue.
*Single WSIs were tiled into 10 000 x 10 000 µm regions before saving to OME TIFF.
#Same histological sections scanned by two different scanner types.
Training Data preparation: Manually annotated datasets
All manual annotations were created by pathology specialists using original whole slide images in QuPath ver. 0.4.1, resulting in 11 classes. Some tissue classes were merged in binary maps (see Table 2). E.g., submucosal tissue (SUBMUC) and adventitial tissue (ADVENT) show certain histological overlaps and both contain large vessels, so that algorithmic differentiation between these two can be difficult and can lead to biased accuracy metrics. The same is true for superficial ulceration regions (ULCUS) and intratumoral/intraluminal necrotic debris (NECROSIS) and for smooth muscle tissue (MUSC_PROP, MUSC_MUC). Finally, nine tissue classes (“1”-“9”) are present in the annotated regions and as well as two additional non-tissue classes: “0” for non-annotated pixels and “10” for slide background).
Table 2. Tissue classes
|
Class code (binary maps) |
Abbreviation |
Description |
|
0 |
|
Non-annotated pixels (should be ignored) |
|
1 |
TUMOR |
Tumor tissue (epithelial), areas with clear high-grade intraepithelial neoplasia/adenoma might be included |
|
2 |
MUC |
Benign mucosa (colonic and ileal) |
|
3 |
TU_STROMA |
Tumoral stroma |
|
4 |
SUBMUC |
Submucosal tissue, including large vessels |
|
4 |
VESSEL |
Blood vessels with muscular wall |
|
4 |
ADVENT |
Adventitial tissue / pericolic fat tissue, including large vessels |
|
5 |
MUSC_PROP |
Muscularis propria |
|
5 |
MUSC_MUC |
Muscularis mucosae |
|
6 |
LYMPH_TIS |
Any forms of lymphatic tissue: lymphatic aggregates, lymph node tissue |
|
7 |
ULCUS |
Ulceration (surface) |
|
7 |
NECROSIS |
Necrotic debris |
|
8 |
MUCIN |
Acellular mucin lakes |
|
9 |
BLOOD |
Bleeding areas – only erythrocytes without any stromal or other tissue |
|
10 |
BACK |
Slide background |
The annotated regions were extracted with corresponding binary maps using QuPath and saved in png format without additional compression (only native scanner image compression applies).
Examples of tissue classes
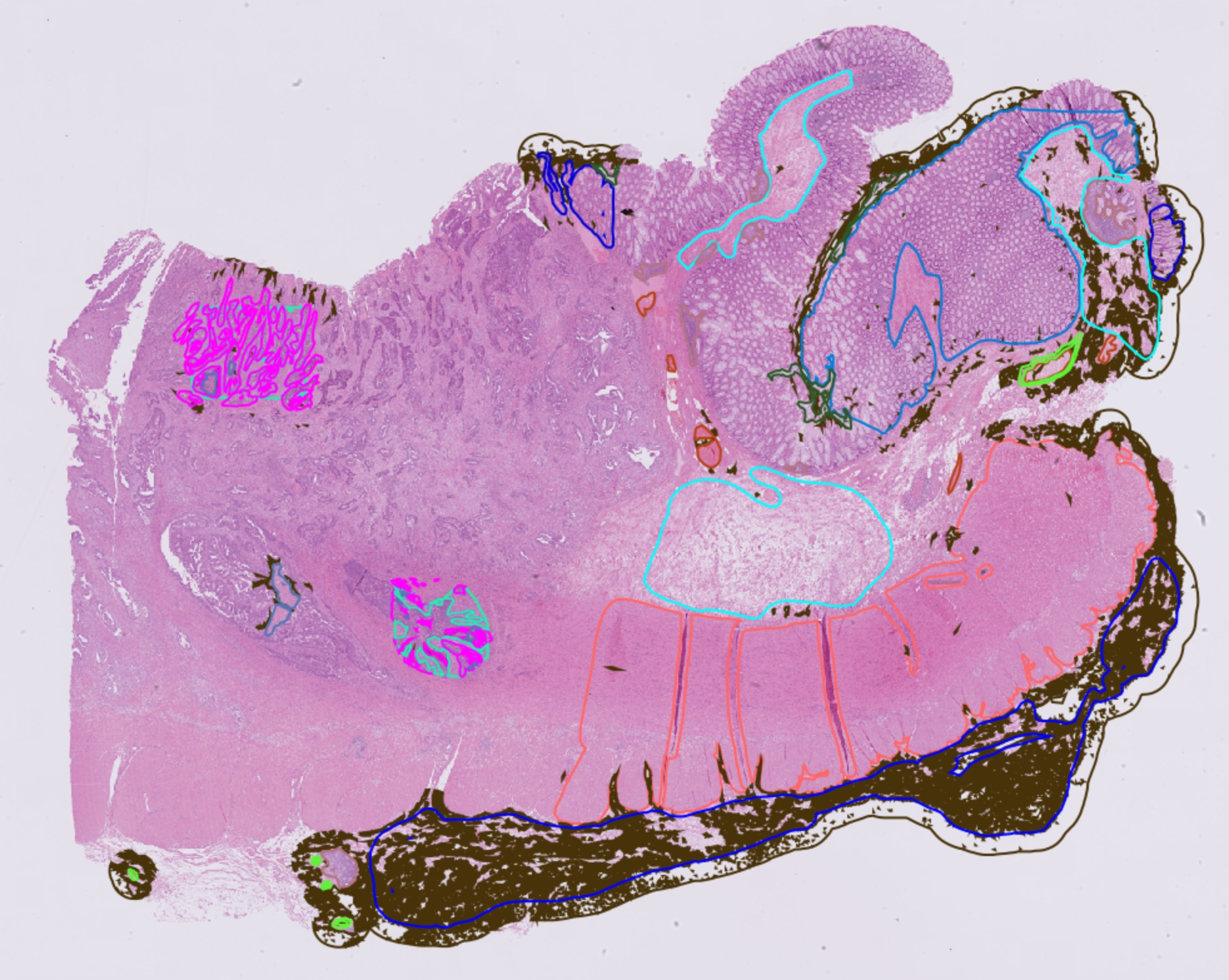
Figure 2. Example of the manually annotated whole slide image before region extraction.
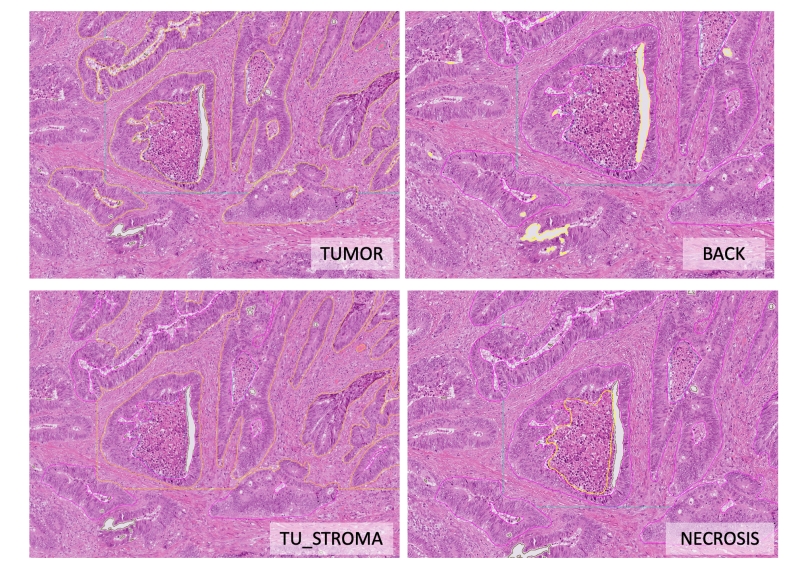
Figure 3. Examples of different tissue classes.
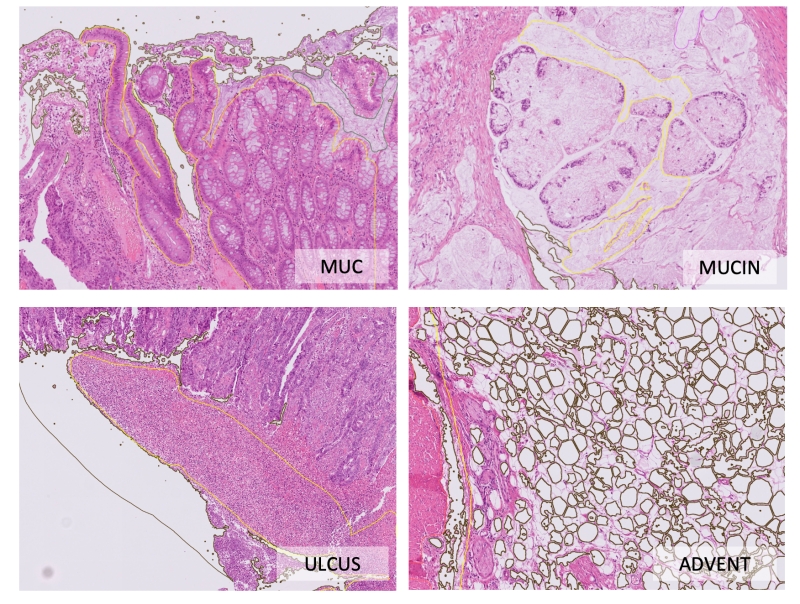
Figure 4. Examples of different tissue classes (continued).

Figure 5. Examples of different tissue classes (continued).
Training Data preparation: Weakly labeled datasets
Weakly labeled datasets stem from four different institutes; one of the datasets is scanned with two different scanners. The slides are sorted according to the presence or absence of the tumor (anywhere in the slide, without any annotation of tumor region; slide-level labels). All whole slide images from all institutes were tiled into areas with a standard size of 10 000 x 10 000 µm. All regions were saved at 20x objective magnification in ome.tiff pyramidal format provided by Bioformats library in QuPath ver. 0.4.1. Additional compression at this step was performed using JPEG2000 lossy algorithm implemented in QuPath. Therefore, several ome.tiff images correspond to one whole slide image. In the case of tumor-bearing slide, the tumor tissue might be in one or more such 10 000 µm regions; this should be accounted for. Some of the 10 000 µm regions from tumor-bearing slides, therefore, might contain no tumor tissue.
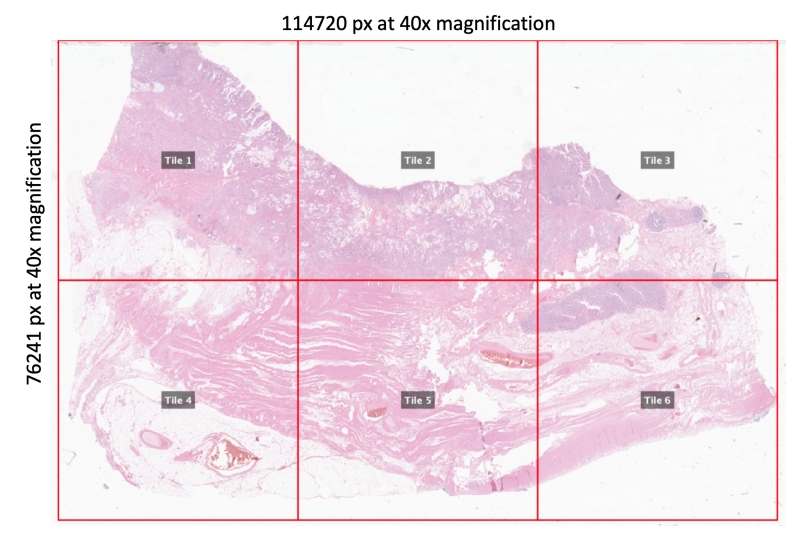
Figure 6. Principle of processing of whole-slide images for weakly labeled datasets. The size of the tiles is 10 000 x 10 000 µm. The actual size in pixels depends on the MPP of the original slide. The 10 000 µm regions are saved under 20x magnification in OME-TIFF format. This example represents a “tumor” slide. Please note that only some of the resulting 10 000 µm regions contain tumor tissue (e.g., Tile 1, 2, and 3), while some might contain only benign tissue (e.g., Tile 4, 5, and 6). This should be considered while using weak slide labels during training.
Validation Data: Structure
During the validation phase (starting on March 1st, 2023), we will provide additional images (Figure 7) that will be used by participants to validate their algorithms according to two test tasks: 1) semantic segmentation accuracy, 2) classification of biopsy slides (tumor yes/no) at the slide level. The output for the second task should be a probability of a slide having a tumor (anywhere) based on the semantic segmentation of biopsy tissue. The participating teams will provide their prediction maps for a manually annotated dataset that will be used for Dice score calculation (Task 1) and the probability of having a tumor for the biopsy slide dataset (Task 2). This information will be processed by Organizers: Dice Score (Task 1), AUROC Score (Task 2), and their average (global score) will be used to update the leaderboards. Slide background class (BACK) will be excluded from the Dice metric calculation.

Figure 7. Structure of SemiCOL challenge validation data.
The principles of data preparation for the validation datasets are similar to the training dataset.
Test Data: Structure
All test datasets are being held privately (Figure 8) and will be used by organizers to evaluate the submitted algorithms, similarly to the validation phase, regarding two test tasks: 1) semantic segmentation accuracy, 2) classification of biopsy slides (tumor yes/no) at the slide level. The output for the second task should be a probability of a slide having a tumor (anywhere) based on the semantic segmentation of biopsy tissue.
The participating teams will submit their algorithms in a standardized form that will be used for Dice score calculation (Task 1) and calculation of the probability of having a tumor for single slides in the biopsy slide datasets / AUROC score for whole datasets (Task 2). Dice scores will be averaged across four test datasets (Task 1) and AUC score will be averaged across six datasets (Task 2). Their average will be used as global score for the selection of the winning algorithms. Slide background class (BACK) will be excluded from the Dice metric calculation.
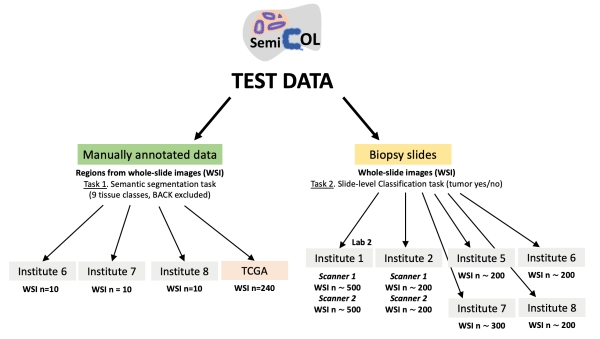
Figure 8. Structure of SemiCOL challenge test data. One of the manually annotated datasets are whole slide images from The Cancer Genome Atlas.
List of participating pathology departments
|
Institute 1 |
University Hospital Cologne, Labs 1 and 2, Cologne, Germany |
|
Institute 2 |
Hospital Wiener Neustadt, Austria |
|
Institute 3 |
University Hospital LMU, Munich, Germany |
|
Institute 4 |
University Hospital Bern, Bern, Switzerland |
|
Institute 5 |
Haukeland University Hospital, Bergen, Norway |
|
Institute 6 |
University Hospital Charité, Berlin, Germany |
|
Institute 7 |
Kameda Medical Center, Nagasaki University, Kamogawa, Japan |
|
Institute 8 |
Medical University of Graz, Graz, Austria |